
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- inflearn
- redis
- Operating System.
- C#
- 에러핸들링
- 10026번
- 열혈 tcp/ip 프로그래밍
- 운영체제
- 우아한 테크 세미나
- 토마토
- 2475번
- OS
- BOJ
- FIFO paging
- 스프링 입문
- C++
- 우아한레디스
- 윤성우 저자
- Four Squares
- n타일링2
- 김영한
- Operating System
- 열혈 TCP/IP 소켓 프로그래밍
- 이펙티브코틀린
- Spring
- 제프리리처
- TCP/IP
- 스프링 핵심 원리
- Window-Via-c/c++
- HTTP
- Today
- Total
나의 브을로오그으
#3. 주소체계와 데이터 정렬 본문
#1. 소켓에 할당되는 IP주소와 PORT번호
IP는 Internet Protocol의 약자이다. 인터넷상에서 데이터 송수신을 목적으로 컴퓨터에 부여하는 값.
PORT번호는 값이 아닌, 프로그램상에서 생성되는 소켓을 구분하기 위해 소켓에 부여되는 번호.
인터넷 주소(Internet Address)
IP Address는 컴퓨터가 서로 데이터를 주고받기 위해 반드시 부여 받아야 한다.
IP 주소체계)
IPv4 (Internet Protocol version 4) 4바이트 주소체계
IPv6 (Internet Protocol version 6) 6바이트 주소체계
두 주소체계의 차이점 : 주소 크기
2010년을 전후로 IP주소의 고갈위험으로 6바이트 주소체계의 표준이 만들어졌지만, 아직까지도 IPv4가 주로 사용되고 있다.
IPv4기준으로 4바이트 IP주소는 네트워크 주소와 호스트(컴퓨터) 주소로 나뉜다.
주소의 형태에 따라 A, B, C, D, E 클래스 분류가 된다.
(참고로 E 클래스는 일반적이지 않은, 예약되어있는 주소체계이다)
| 분류 | 1BYTE | 1BYTE | 1BYTE | 1BYTE |
| 클래스A | 네트워크 ID | 호스트 ID | 호스트ID | 호스트ID |
| 클래스B | 네트워크ID | 네트워크ID | 호스트ID | 호스트ID |
| 클래스C | 네트워크ID | 네트워크ID | 네트워크ID | 호스트ID |
| 클래스D | 네트워크ID | 네트워크ID | 네트워크ID | 네트워크ID |
네트워크 주소(ID) : 네트워크의 구분을 위한 IP주소의 일부를 말한다. 예를 들어서 WWW.SEMI.COM이라는 회사의 모대리에게 데이터를 전송한다고 가정하하자. 그런데 이 회사의 컴퓨터는 하나의 로컬 네트워크로 연결되어 있다.
그렇다면 먼저 SEMI.COM의 네트워크로 데이터를 전송하는 것이 우선이다. 즉, 처음부터 4바이트 IP주소 전부를 참조해서 모대리의 컴퓨터로 데이터가 전송되는 것이 아니라, 4바이트 IP주소 중에서 네트워크 주소만을 참조해서 일단 SIMI.COM의 네트워크로 데이터가 전송된다. 그리고 SEMI.COM의 네트워크로 데이터가 전송되었다면, 해당 네트워크는(네트워크를 구성하는 라우터는) 전송된 데이터의 호스트 주소(호스트 ID)를 참조하여 모대리의 컴퓨터로 데이터를 전송해준다.
정리)
1. 무회사 모대리한테 데이터를 보내고 싶어서 보낸다.(참고로 이 회사는 로컬 네트워크로 연결되어 있다. 결국 네트워크 주소는 똑같고, 호스트 주소만 다른거임)
2. 이제 데이터를 해당 네트워크(라우터)로 보낸다.
3. 전송된 데이터를 라우터에서 호스트 주소를 참조하여 모대리 컴퓨터로 데이터를 전송해준다.
여기서!! 네트워크로 데이터가 전송된다는 말은, 네트워크를 구성하는 라우터(Router)또는 스위치(Switch)로 데이터가 전송됨을 뜻한다. 그러면 데이터를 전송 받은 라우터는 데이터에 적혀있는 호스트 주소를 참조하여 호스트에 데이터를 전송해준다.
[라우터와 스위치]
네트워크를 구성하려면 외부로부터 수신도니 데이터를 호스트에 전달하고, 호스트가 전달하는 데이터를 외부로 송신해주는 물리적인 장치가 필요하다. 이를 가리켜 라우터 또는 스위치라고 한다. 이것도 일종의 컴퓨터일 뿐이다. 다만, 특수한 목적을 가지고 설계 및 운영되는 컴퓨터이기 때문에 라우터 또는 스위치라는 별도의 이름을 붙여준 것이다. 그래서 일반 컴퓨터도 적절한 소프트웨어 설치와 구성을 갖춘다면 라우터로 동작시킬 수 있다. 그리고 라우터보다 기능적으로 작은 것을 가리켜 스위치라고 부르는데, 둘다 같은 기능이므로 같은 의미로 사용된다.
클래스 별 네트워크 주소와 호스트 주소의 경계
IP주소의 첫 번째 바이트만 딱 보면 네트워크 주소가 몇 바이트인지 판단이 가능하다.
네트워크 주소의 크기
- 클래스 A의 첫 번째 바이트 범위 0 이상 127 이하
- 클래스 B의 첫 번째 바이트 범위 128 이상 191 이하
- 클래스 C의 첫 번째 바이트 범위 192 이상 223 이하
즉, 클래스 A의 첫번째 비트는 0으로 시작, 클래스 B의 첫 두비트는 항상 10으로 시작, 클래스 C의 첫 세비트는 항상 110으로 시작.
이러한 기준이 정해져 있기 때문에 소켓을 통해서 데이터를 송수신할 때, 우리가 별도로 신경 쓰지 않아도 네트워크로 데이터가 이동하고 이어서 최종 목적지인 호스트로 데이터가 전송되는 것이다.
소켓의 구분에 활용되는 PORT번호
IP(Address)는 컴퓨터를 구분하기 위한 목적으로 존재한다. 따라서 단지, 데이터를 전송하는 것이라면 IP Address만 알아도 된다. 그러나 이것만 가지고 데이터를 수신해야 하는 최종 목적지인 응용 프로그램으로 전송 할 수는 없다.
예)
동영상 시청과 인터넷 서핑을 동시에 한다면, 동영상 데이터 수신을 위한 소켓 하나와 인터넷 정보 수신을 위한 소켓 하나가 최소 필요하다.쉽게 말해 외부로부터 우리의 컴퓨터로 들어온 데이터를 동영상 플레이어에게 전달할지, 브라우저로 전달할지를 구분해서 전달되어야 한다.
" 나는 데이터를 주고받는 P2P 프로그램을 개발했다. 이 프로그램은 하나의 파일을 블록단위로 나눠서 동시에 둘 이상의 컴퓨터로부터 데이터를 전송 받는다. "
이런 가정을 세웠다고 해보자. 그러면 두개의 컴퓨터로부터 데이터를 받으려면 최소 소켓이 2개 필요 할 것이다. 이 둘 소켓은 어떻게 구분해야 할까?
우리의 컴퓨터에는 NIC(Network Interface Card)라고 불리는 데이터 송수신장치가 하나씩 달려있다. IP는 데이터를 NIC를 통해 컴퓨터 내부로 전송하는데 사용된다.그러나 컴퓨터 내부로 전송된 데이터를 소켓에 적절히 분배하는 작업은 OS가 담당한다. 이 때 OS는 PORT번호를 활용한다. 즉, NIC를 통해서 수신된 데이터 안에는 PORT번호가 새겨져 있다. 바로 이 정보를 참조해서 일치하는 PORT번호의 소켓에 데이터를 전달하는 것이다.
이렇듯 PORT번호는 하나의 OS내에서 소켓을 구분하기 위해 사용되기 때문에 소켓에 중복된 PORT번호를 할당 할 수 없다. 또한 PORT번호는 16비트이므로 PORT번호의 범위는 0이상 65535이하이다. 여기서 0~1023은 Well-Known-PORT라고 해서 이미 특정 프로그램에 예약되어 있다. 그래서 이 범위의 값을 제외한 다른 값을 할당해야 한다.
또한 TCP소켓과 UDP소켓은 PORT번호를 공유하지 않기 때문에 중복되도 상관없다. TCP소켓의 9190PORT를 할당했다면, 다른 TCP소켓에는 9190을 할당 할 수 없지만, UDP 소켓에는 할당 가능하다.
정리)
우리가 흔히 말하는 데이터 전송의 목적지 주소에는 IP주소뿐만 아니라 PORT번호도 포함이 된다. 그래야 최종 목적지인 응용프로그램에(응용프로그램 소켓)까지 전달 할 수 있기 때문이다.
#2. 주소정보의 표현
IPv4 기반의 주소표현을 위한 구조체
주소정보를 담을 때에는 다음 세가지 물음의 답을 담아야 한다.
Q1) 어떠한 주소체계를 이용하는가? (Protocol Family)
A1) IPv4 기반 주소체계를 사용한다.
Q2) IP주소는 어떻게 되는가?
A2) 123.456.789.1 이다.
Q3) PORT번호는 어떻게 되는가?
A3) 9999이다.
응용 프로그램상에서 IP주소와 PORT번호 표현을 위한 구조체가 정의되어있는데, 위의 정보를 담아야 한다.
struct sockaddr_in
{
sa_family_t sin_family; //주소체계(Address Family)
unit16_t sin_port; // 16비트 TCP/UDP PORT번호
struct in_addr sin_addr; // 32비트 IP주소
char sin_zero[8]; // 사용되지 않음
}
struct in_addr
{
in_addr_t s_addr; // 32비트 IPv4 인터넷 주소
}uint16_t, in_addr_t와 같은 자료형은 POSIX(Portable Operating System Interface)에서 찾을 수 있다.
| 자료형 이름 | 자료형에 담길 정보 | 선언된 헤더 파일 |
| int8_t uint8_t int16_t uint16_t int32_t uint32_t |
singed 8-bit int unsigned 8-bit int (unsigned char) signed 16-bit int unsigned 16-bit int (unsigned short) signed 32-bit int unsigned 32-bit int (unsigned long) |
sys/types.h |
| sa_family_t socklen_t |
주소체계(address family) 길이정보(length of struct) |
sys/socket.h |
| in_addr_t in_port_t |
IP주소정보, uint32_t로 정의되어 있음 PORT번호정보, uint16_t로 정의되어 있음 |
netinet/in.h |
(이렇게 자료형을 별도 정의한 이유는 확장성을 고려하여 int32_t라는 자료형을 사용하게되면 4바이트 자료형이라는 것을 보장받을 수 있음)
구조체 sockaddr_in의 멤버에 대한 분석
- 멤버 sin_family
프로토콜 체계마다 적용되는 주소체계가 다르다. IPv4의 경우 4바이트 주소체계를 사용하며, IPv6에서는 16바이트 주소체계를 사용한다.
| 주소체계(Address Family) | 의미 |
| AF_INET | IPv4 인터넷 프로토콜에 적용하는 주소체계 |
| AF_INET6 | IPv6 인터넷 프로토콜에 적용하는 주소체계 |
| AF_LOCAL | 로컬 통신을 위한 유닉스 프로토콜의 주소체계 |
- 멤버 sin_port
16비트 PORT번호를 저장한다. 단, '네트워크 바이트 순서'로 저장해야 하는데, 이 멤버는 PORT번호 저장보다 오히려 네트워크 바이트 순서로 저장해야 한다는 사실이 더 중요하다.
- 멤버 sin_addr
32비트 IP주소정보를 저장한다. 이것도 '네트워크 바이트 순서'로 저장해야 한다. sin_addr의 타입이 in_addr 구조체 타입인데 이 구조체의 유일한 멤버가 uint32_t로 선언되어 있으므로 간단히 32비트 정수자료형으로 인식해도 된다.
- 멤버 sin_zero
특별한 의미가 없는 멤버이다. 구조체 sockaddr과 크기를 일치시키기 위해 삽입된 멤버이다. 그러나 반드시 0으로 채워야한다. 0으로 채우지 않으면 결과가 이상하게 나온다.
struct sockaddr_in serv_addr;
...
if (bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr))== -1)
{
error_handling("bind() error");
}여기서 중요한 인자는 2번째 인자이다. bind() 함수는 sockaddr의 구조체 변수의 주소를 요구한다.
앞에서 이야기한 주소 체계, PORT번호, IP 주소 정보를 담고 있는 sockaddr 구조체 변수의 주소 값을 요구하는 것이다.
강제 형변환을 하는 이유는 sockaddr이 가지고 있는 멤버가 불편하게 정의되어 있기 때문이다.
struct sockaddr
{
sa_familt_t sin_family; // 주소체계(Address Family)
char sa_data[14]; // 주소정보
}sa_data 주소정보에는 IP주소와 PORT번호가 포함되어야 하고, 이 두가지 정보를 담고 남은 부분은 0으로 채울 것을 bind()함수에서 요구한다. 그런데 이는 주소정보를 담기에 매우 불편한 요구사항이다. 따라서 sockaddr_in이 등장했다.
sockaddr_in의 구조체 멤버를 채우면, 형변환을 통해서 채운 데이터가 구조체 변수의 바이트 배열이 되고 이는 bind()함수가 요구하는 바대로 데이터를 채운 효과가 나온다.
[sin_family]
sockaddr_in은 IPv4의 주소정보를 담기 위해 정의된 구조체이다. 그럼에도 불구하고 주소체계 정보를 구조체 멤버 sin_family에 별도로 저장하는 이유가 궁금 할 수 있다. 이는 앞서 언급한대로 sockaddr과 관련이 있다. sockaddr은 IPv4의 주소정보만을 담기 위해 정의된 구조체가 아니다. 주소정보를 담는 배열 sa_data의 크기가 14바이트인 것만 봐도 그러하다.따라서 구조체 sockaddr에서는 주소체계 정보를 구조체 멤버 sin_family에 저장할 것을 요구하고 있다. 때문에 구조체 sockaddr과 동일한 바이트 열을 편히 구성하기 위해서 정의된 구조체 sockaddr_in에도 주소체계 정보를 담기 위한 멤버가 존재하는 것이다.
#3. 네트워크 바이트 순서와 인터넷 주소 변환
이번에는 CPU에 따라서 CPU가 메모리에 데이터를 저장하는 방식에 대해 알아보자.
- 빅 엔디안(Big Endian) : 상위 바이트의 값을 작은 번지수에 저장하는 방식
- 리틀 엔디안(Little Endian) : 상위 바이트의 값을 큰 번지수에 저장하는 방식
예)
0x12345678을 메모리에 저장한다면,
0x20번지, 0x21번지, 0x22번지, 0x23번지
빅 엔디안 : 0x12, 0x34, 0x56, 0x78
리틀 엔디안 : 0x78, 0x56, 0x34, 0x12
CPU의 데이터 저장방식을 의미하는 '호스트 바이트 순서(Host Byte Order)'는 CPU에 따라서 차이가 난다. 주로 인텔 계열 CPU는 리틀 엔디안 방식으로 데이터를 저장한다.
만약에 호스트 바이트 순서가 다른 컴퓨터끼리 데이터를 주고받는다면?
한쪽에서는 해당 데이터를 잘못 받게 된다.(0x1234 -> 0x3412) 따라서 이같은 문제를 해결하기 위해
네트워크를 통해서 데이터를 전송할 때에는 통일된 기준으로 데이터를 전송하기로 약속하였으며, 이 약속을 가리켜
'네트워크 바이트 순서(Network Byte Order)'라 한다.
네트워크 바이트 순서는 아주 간단하다. = 빅 엔디안 방식으로 통신
즉, 네트워크상에서 데이터를 전송할 때에는 데이터의 배열을 빅 엔디안 기준으로 변경해서 송수신하기로 약속한 것이다. 때문에 모든 컴퓨터는 수신된 데이터가 네트워크 바이트 순서로 정렬되어 있음을 인식해야 하며, 리틀 엔디안 시스템에서는 데이터를 전송하기에 앞서 빅 엔디안의 정렬방식으로 데이터를 재정렬해야한다.
바이트 순서의 변환(Endian Conversions)
이제 sockaddr_in 구조체의 멤버를 채우기 전에 먼저 네트워크 바이트 순서로 변환해서 저장해야 한다.
unsigned short htons(unsigned short);
unsigned short ntohs(unsigned short);
unsigned long htonl(unsigned long);
unsigned long ntohl(unsigned long);- htons에서의 h는 호스트(host) 바이트 순서를 의미한다.
- ntons에서의 n은 네트워크(network) 바이트 순서를 의미한다.
(hton = host to network를 의미하며, s와 l은 반환타입, 인자타입을 의미한다. 추가적으로 s의 경우 PORT변환에 사용되고 l의 경우 IP 주소 변환에 사용된다.)
그렇다면? 빅 엔디안 방식으로 동작하는 CPU를 가진 컴퓨터라면 변환할 필요가 없을까? 맞는 말이지만, 그럼에도 불구하고 리틀 엔디안, 빅 엔디안 상관 없이 동작할 수 있도록 코드를 작성 할 필요가 있다.
/* Linux */
#include <stdio.h>
#include <arpa/inet.h>
int main(int argc, char* argv[])
{
unsigned short host_port = 0x1234;
unsigned short net_port;
unsigned long host_addr = 0x12345678;
unsigned long net_addr;
net_port = htons(host_port);
net_addr = htonl(host_addr);
printf("Host ordered port: %#x \n", host_port);
printf("Network ordered port: %#x \n", net_port);
printf("Host ordered address: %#lx \n", host_addr);
printf("Network ordered address: %#lx \n", net_addr);
return 0;
}현재 가장 많이 쓰이는 CPU는 인텔과 AMD CPU인데 둘다 리틀 엔디안을 기준으로 정렬한다.
데이터 전송하기 전에 다 바꿔줘야 하나?
데이터 송수신 기준이 '네트워크 바이트 순서'이다 보니, 데이터를 전송하기 전에 직접 네트워크 바이트 순서로 데이터를 변경해야 한다고 생각할 수 있다. 그리고 수신된 데이터도 역시 변환 과정을 거쳐서 메모리에 저장해야 한다. 이렇게 수동으로 매변 변환해야 한다면 끔직하다. 다행히도 변환 과정은 자동으로 이루어진다. 그래서 우리는 sockaddr_in 구조체 멤버에 데이터를 채울 때 이외에는 바이트 순서를 신경 쓰지 않아도 된다.
#4. 인터넷 주소의 초기화와 할당
문자열 정보를 네트워크 바이트 순서의 정수로 변환하기
sockaddr_in안에서 주소정보를 저장하기 위해 선언된 멤버는 32비트 정수형으로 정의되어 있다. 문자열 정보로 넘어온 데이터를 정수형으로 바꿔야 한다는 의미이다. 이때 특정 함수를 사용하면 쉽게 변환이 가능하다.
#include <arpa/inet.h>
in_addr_t inet_addr(const char* string);
-> 성공 시 빅 엔디안으로 변환된 32비트 정수 값, 실패 시 INADDR_NONE반환예)
211.214.107.99와 같이 점이 찍힌 10진수로 표현된 문자열을 전달하면, 해당 문자열 정보를 참조해서 IP주소 정보를 32비트 정수형으로 반환한다. 당연히 반환하는 정수는 네트워크 바이트 순서로 정렬되어 있다.
[inet_addr.c]
#include <stdio.h>
#include <arpa/inet.h>
int main(int argc, char* argv[])
{
char* addr1 = "1.2.3.4";
char* addr2 = "1.2.3.256";
unsigned long conv_addr = inet_addr(addr1);
if (conv_addr == INADDR_NONE)
{
printf("Error occured! \n");
}
else
{
printf("Network ordered integer addr: %#lx \n", conv_addr);
}
conv_addr = inet_addr(addr2);
if (conv_addr == INADDR_NONE)
{
printf("Error occureded \n");
}
else
{
printf("Network ordered integer addr: %#lx \n", conv_addr);
}
return 0;
}
// 실행결과
Network ordered integer addr: 0x4030201
Error occureded위의 실행결과 처럼 inet_addr()함수는 32비트 정수형태로 IP주소를 바꾸는것 뿐만아니라 유효하지 못한 IP주소에 대한 오류검출 능력도 갖고 있다. 그리고 출력 결과를 통해서 네트워크 바이트 순서로 정렬되었음을 알 수 있다.
#include <arpa/inet.h>
int inet_aton(const char* string, struct in_addr* addr);
-> 성공 시 1(true), 실패 시 0(false) 반환
string : 변환될 IP주소 정보를 담고 있는 문자열의 주소 값 전달.
addr : 변환된 정보를 저장할 in_addr 구조체 변수의 주소 값 전달.
[inet_aton.c]
#include <stdio.h>
#include <stdlib.h>
#include <arpa/inet.h>
void error_handling(char* message);
int main(int argc, char* argv[])
{
char* addr = "127.232.124.79";
struct sockaddr_in addr_inet;
if (!inet_aton(addr, &addr_inet.sin_addr))
{
error_handling("Conversion error");
}
else
{
printf("Network ordered integer addr : %#x \n", addr_inet.sin_addr.s_addr);
}
return 0;
}
void error_handling(char* message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
return;
}(이로써 변환된 주소를 직접 저장하는 일도 덜수 있게 되었다.)
inet_aton() 함수의 반대기능을 제공하는 함수
#include <arpa/inet.h>
char* inet_ntoa(struct in_addr adr);
-> 성공 시 변환된 문자열의 주소 값, 실패 시 -1 반환이 함수에서 주의할 점은 메모리 주소를 반환하기 때문에 따로 메모리를 할당해서 해당 문자열 정보를 저장하는 것이 좋다.
즉, inet_ntoa가 재호출되면 반환된 문자열 주소가 유효하지 않기 때문에 따로 메모리 공간을 할당하는 것이 좋다.
[inet_ntoa.c]
#include <stdio.h>
#include <string.h>
#include <arph/inet.h>
int main(int argc, char* argv[])
{
struct sockaddr_in addr1, addr2;
char* str_ptr;
char str_arr[20];
arr1.sin_addr.s_addr = htonl(0x1020304);
arr2.sin_addr.s_addr = htonl(0x1010101);
str_ptr = inet_ntoa(addr1.sin_addr);
strcpy(str_arr, str_ptr);
printf("Dotted-Decimal notation1: %s \n", str_ptr);
inet_ntoa(addr2.sin_addr);
printf("Dotted-Decimal notation2: %s \n", str_ptr);
printf("Dotted-Decimal notation3: %s \n", str_arr);
return 0;
}
// 실행 결과
Dotted-Decimal notation1: 1.2.3.4
Dotted-Decimal notation2: 1.1.1.1
Dotted-Decimal notation3: 1.2.3.4(inet_ntoa()를 재호출할때는 반환된 문자열의 주소를 str_ptr에 저장했기 때문에 따로 받을 필요가 없고, str_ptr를 출력하면 변경된 문자열을 볼 수 있음.)
인터넷 주소의 초기화
소켓생성과정에서 흔히 등장하는 인터넷 주소정보의 초기화 방법
struct sockaddr_in addr;
char* serv_ip = "211.125.165.13"; // IP주소 문자열 선언
char* serv_port = "9190"; // PORT번호 문자열 선언
memset(&addr, 0, sizeof(addr)); // 구조체 변수 addr의 모든 멤버 0으로 초기화
addr.sin_family = AF_INET; // 주소체계 지정
addr.sin_addr.s_addr = inet_addr(serv_ip); // 문자열 기반의 IP주소 초기화
addr.sin_port = htons(atoi(serv_port)); // 문자열 기반의 PORT번호 초기화사실 이렇게 IP주소와 PORT번호를 직접 넣어주는것은 좋지 못하다. main문의 인자로 받아오는게 적합하다.
INADDR_ANY
서버 소켓 생성 시 IP주소 입력을 매번 하는것은 번거롭다. 따라서 다음과 같이 초기화해도 된다.
struct sockaddr_in addr;
char* serv_port = "9190";
memset(&addr, 0, sizeof(addr));
addr.sin_family=AF_INET;
addr.sin_addr.s_addr = htonl(INADDR_ANY);
addr.sin_port = htons(atoi(serv_port));INADDR_ANY상수값을 넣어 초기화하면 소켓이 동작하는 컴퓨터의 IP주소를 자동으로 할당해 준다. 컴퓨터내에 2개이상의 IP를 할당받아서 사용하는 것을 Multi-homed 라고 한다. (일반적으로 라우터에 해당) 할당 받은 IP중 어떤 주소를 통해서 데이터가 들어오더라도 PORT번호만 일치하면 수신할 수 있게 된다. 서버에서 가장 선호하는 구현 방식이다.
서버 소켓 생성시 IP주소가 필요한 이유
서버 소켓은, 생성시 자신이 속한 컴퓨터의 IP주소로 초기화가 이뤄져야 한다.즉, 초기화할 IP주소가 뻔하다! 그럼에도 불구하고 IP주소의 초기화를 요구하는 것에 의문을 가질 수 없다. 하지만 위에서 말했듯 하나의 컴퓨터에 둘 이상의 IP주소가 할당될 수 있다는 사실을 통해 이해 가능하다. IP주소는 컴퓨터에 장착된 NIC(랜카드)의 개수만큼 부여가 가능하다. 그리고 이러한 경우에는 서버 소켓이라 할지라도 어느 IP주소로 들어오는(어느 NIC로 들어오는) 데이터를 수신할지 결정해야 한다. 때문에 서버 소켓의 초기화 과정에서 IP주소 정보를 요구하는 것이다. 반면 NIC가 하나뿐인 컴퓨터라면 주저없이 INADDR_ANY를 이용해서 초기화하는 것이 간편하다.
※ 참고 : 127.0.0.1은 루프백 주소(loopback address)라 하며, 컴퓨터 자신의 IP주소를 의미한다.
소켓에 인터넷 주소 할당하기
#include <sys/socket.h>
int bind(int sockfd, struct sockaddr* myaddr, socklen_t addrlen);
-> 성공 시 0, 실패 시 -1반환
sockfd : 주소정보를(IP와 PORT를) 할당할 소켓의 파일 디스크립터
myaddr : 할당하고자 하는 주소정보를 지니는 구조체 변수의 주소 값
addrlen : 두 번째 인자로 전달된 구조체 변수의 길이정보
소켓 초기화 과정 정리
int serv_sock;
struct sockaddr_in serv_addr;
char* serv_port = "9190";
/* 서버 소켓(리스닝 소켓) 생성 */
serv_sock = socket(PF_INET, SOCKET_STREAM, 0);
/* 주소정보 초기화 */
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port = htons(atoi(serv_port));
/* 주소정보 할당 */
bind(serv_sock, (struct sockaddr*)serv_addr, sizeof(serv_addr));
#5. 윈도우 기반으로 구현하기
윈도우에서도 sockaddr_in의 사용방법, 의미까지 전부 똑같다.
[endian_conv_win.c]
#include <stdio.h>
#include <WinSock2.h>
#pragma comment(lib, "ws2_32.lib")
void ErrorHandling(const char* message);
int main(int argc, char* argv[])
{
WSADATA wsaData;
unsigned short host_port = 0x1234;
unsigned short net_port;
unsigned long host_addr = 0x12345678;
unsigned long net_addr;
if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0)
{
ErrorHandling("WSAStartup() error!");
}
net_port = htons(host_port);
net_addr = htonl(host_addr);
printf("Host ordered port: %#x \n", host_port);
printf("Network ordered port: %#x \n", net_port);
printf("Host ordered address: %#x \n", host_addr);
printf("Network ordered address: %#x \n", net_addr);
WSACleanup();
return 0;
}
void ErrorHandling(const char* message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
}[실행결과]

현재 저는 인텔, amd계열 CPU를 사용하므로 데이터를 리틀엔디안 방식으로 저장하고,
네트워크 통신 시 전송 방식은 "빅엔디안 방식"으로 전송되므로 뒤집혀있다.
함수 inet_addr, inet_ntoa의 윈도우 기반 사용 예
앞서 리눅스 기반에서는 각각 별도 예제로 보였지만, 여기서는 한번에 보이겠다. 윈도우에서는 inet_aton() 함수가 별도로 존재하지 않으므로 생략한다.
#include <stdio.h>
#include <string.h>
#include <WinSock2.h>
#include <WS2tcpip.h>
#pragma comment(lib, "ws2_32.lib")
void ErrorHandling(const char* message);
int main(int argc, char* argv[])
{
WSADATA wsaData;
if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0)
{
ErrorHandling("WSAStartup() error!");
}
/* inet_addr 함수 호출 예 */
const char* addr = "127.212.124.78";
// inet_addr() -> deprecated
//unsigned long conv_addr = inet_addr(addr);
//if (conv_addr == INADDR_NONE)
//{
// prinitf("Error occured! \n");
//}
//else
//{
// printf("Network ordered integer addr: %#lx \n", conv_addr);
//}
unsigned long conv_addr;
if (inet_pton(AF_INET, addr, &conv_addr) == -1)
{
printf("Error occured! \n");
}
else
{
printf("Network ordered integer addr: %#lx \n", conv_addr);
}
/* inet_ntoa 함수의 호출 예 */
{
struct sockaddr_in addr;
char* strPtr;
char strArr[20];
addr.sin_family = AF_INET;
addr.sin_addr.S_un.S_addr = htonl(0x1020304);
// inet_ntoa() -> deprecated
//strPtr = inet_ntoa(addr.sin_addr);
//strcpy_s(strArr, sizeof(strArr), strPtr);
inet_ntop(AF_INET, &addr.sin_addr, strArr, sizeof(strArr));
printf("Dotted-Decimal notation3 %s \n", strArr);
}
WSACleanup();
return 0;
}
void ErrorHandling(const char* message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
}※ inet_addr()와 inet_ntoa() 함수가 deprecated(사용권장하지 않음)되었으므로
WS2tcpip.h파일을 추가하고,
inet_pton()과 inet_ntop()함수를 사용했다.
(보기 쉽게 하려고 중괄호를 사용하여 구분했다.)
[실행결과]

윈도우에서 소켓에 인터넷 주소 할당하기
리눅스에서 소켓에 인터넷 주소를 할당하는 과정과 동일하다.
SOCKET servSock;
struct sockaddr_in servAddr;
const char* servPort = "9190";
/* 서버 소켓 생성 */
servSock = socket(PF_INET, SOCKET_STREAM, 0);
/* 주소정보 초기화 */
memset(&servAddr, 0, sizeof(servAddr));
servAddr.sin_family = AF_INET;
servAddr.sin_addr.S_un.S_addr = htonl(INADDR_ANY);
servAddr.sin_port = htons(atoi(servAddr));
/* 주소정보 할당 */
bind(servSock, (struct sockaddr*)servAddr, sizeof(servAddr));(리눅스에서의 방식과 거의 똑같음)
WSAStringToAddress & WSAAdressToString
윈속2에서 추가된 변환함수들이다. 이 둘은 inet_ntoa, inet_addr 함수와 기능은 같으나 다양한 프로토콜에 적용 가능하다는 장점이 있다. 즉, IPv4 뿐만아니라 IPv6에서도 적용 가능하다. 단, 리눅스와 호환되지 않는다는 단점이 있다.
#include <WinSock2.h>
INT WSAStringToAddress(
LPTSTR AddressString, INT AddressFamily, LPWSAPROTOCOL_INFO lpProtocolInfo,
LPSOCKADDR lpAddress, LPINT lpAddressLength
);
-> 성공 시 0, 실패 시 SOCKET_ERROR 반환AddressString : IP와 PORT번호를 담고 있는 문자열의 주소 값 전달.
AddressFamily : 첫 번째 인자로 전달된 주소정보가 속하는 주소체계 정보전달.
lpProtocolInfo : 프로토콜 프로바이더(Provider) 설정, 일반적으로 NULL 전달.
lpAddress : 주소정보를 담을 구조체 변수의 주소 값 전달.
lpAddressLength : 네 번째 인자로 전달된 주소 값의 변수 크기를 담고 있는 변수의 주소 값 전달.
#include <WinSock2.h>
INT WSAAddressToString(
LPSOCKADDR lpsaAddress, DWORD dwAddressLength,
LPWSAPROTOCO_INFO lpProtocolInfo, LPTSTR lpszAddressString,
LPDWORD lpdwAddressStringLength
);
-> 성공 시 0, 실패 시 SOCKET_ERROR 반환lpsaAddress : 문자열로 변환할 주소정보를 지니는 구조체 변수의 주소 값 전달.
dwAddressLength : 첫 번째 인자로 전달된 구조체 변수의 크기 전달.
lpProtocolInfo : 프로토콜 프로바이더(Provider)설정, 일반적으로 NULL 전달.
lpszAddressString : 문자열로 변환된 결과를 저장할 배열의 주소 값 전달.
lpdwAddressStringLength : 네 번째 인자로 전달된 주소 값의 배열 크기를 담고 있는 변수의 주소 값 전달.
[참고]
Desktop\study_c_c++\TCP_IP_Socket_22_06_27\TCP_IP_Socket_22_06_27\conv_addr_win.c(23,2): warning C4996: 'WSAStringToAddressA': Use WSAStringToAddressW() instead or define _WINSOCK_DEPRECATED_NO_WARNINGS to disable deprecated API warnings
Desktop\study_c_c++\TCP_IP_Socket_22_06_27\TCP_IP_Socket_22_06_27\conv_addr_win.c(26,2): warning C4996: 'WSAAddressToStringA': Use WSAAddressToStringW() instead or define _WINSOCK_DEPRECATED_NO_WARNINGS to disable deprecated API warnings
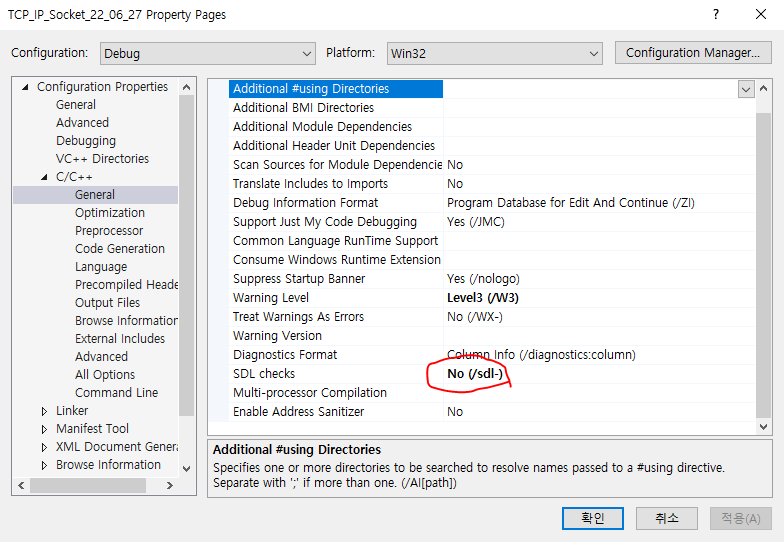
다음과같은 deprecated API라는 오류가 뜬다면 프로젝트 옵션 -> C/C++ -> SDL검사 를 아니요로 변경하자.
[conv_addr_win.c]
#undef UNICODE
#undef _UNICODE
#include <stdio.h>
#include <WinSock2.h>
#pragma comment(lib, "ws2_32.lib")
int main(int argc, char* argv[])
{
char* strAddr = "203.211.218.102:9190";
char strAddrBuf[50];
SOCKADDR_IN servAddr;
int size;
WSADATA wsaData;
WSAStartup(MAKEWORD(2, 2), &wsaData);
size = sizeof(servAddr);
WSAStringToAddress(strAddr, AF_INET, NULL, (SOCKADDR*)&servAddr, &size);
size = sizeof(strAddrBuf);
WSAAddressToString((SOCKADDR*)&servAddr, sizeof(servAddr), NULL, strAddrBuf, &size);
printf("Second conv result: %s", strAddrBuf);
WSACleanup();
return 0;
}#undef : 기존에 정의된 매크로를 해제하는 경우에 사용한다. VC++ 자체적으로 UNICODE, _UNICODE 두 매크로를 정의하는데, 이걸 해제하지 않으면 유니코드 기반의 WSAStringToAddressW() 함수가 호출된다. 꼭 하자.
WSAStringToAddress() 함수 : 문자열 기반의 주소를 구조체 변수에 주소 정보를 채워준다. (servAddr)
WSAAdressToString() 함수 : 역으로 주소정보를 문자열의 형태로 반환한다.

[내용 확인문제]
01. IP주소 체계인 IPv4와 IPv6의 차이점은 무엇인가? 그리고 IPv6의 등장배경은 어떻게 되는가?
답)
IPv4는 4바이트 주소체계이며 IPv6는 16바이트 주소체계이다. IPv6는 IPv4체계의 주소가 고갈될 것을 고려하여 더욱 크기가 큰 표준 주소체계인 IPv6가 나왔다. 그러나 IPv4를 더 많이 사용한다.
02. 회사의 로컬 네트워크에 연결되어 있는 개인 컴퓨터에 데이터가 전송되는 과정을, IPv4의 네트워크 ID와 호스트 ID, 그리고 라우터의 관계를 기준으로 설명하여라.
답)
외부에서 데이터가 전송될때 우선 네트워크 ID(주소)를 참조하여 회사 네트워크(라우터)로 전송된다. 이후 라우터는 호스트 ID를 참조하여 최종적으로 개인 컴퓨터로 전송된다.
03. 소켓의 주소는 IP와 PORT번호 두 가지로 구성된다. 그렇다면 IP가 필요한 이유는 무엇이고, PORT번호가 필요한 이유는 또 무엇인가? 다시 말해서, IP를 통해서 구분되는 대상은 무엇이고, PORT 번호를 통해서 구분되는 대상은 또 무엇인가?
답)
IP는 각각의 컴퓨터를 구분하는 주소이며, PORT번호는 소켓을 구분하는 번호이다.
04. IP주소의 클래스를 결정하는 방법을 설명하고, 이를 근거로 다음 IP주소들이 속하는 클래스를 판단해보자.
1) 213.121.212.102
2) 120.101.122.89
3) 129.78.102.211
답)
IP주소의 첫번째 바이트의 크기에 따라 클래스가 나뉜다.
0~127 : 클래스 A, 128 ~ 191 : 클래스 B, 192 ~ 223 : 클래스 C
1) 클래스 C, 2) 클래스 A, 3) 클래스 B
05. 컴퓨터는 라우터 또는 스위치라 불리는 물리적인 장치를 통해서 인터넷과 연결된다. 그렇다면 라우터 또는 스위치의 역할이 무엇인지 설명해보자.
답)
라우터를 통해 독립적인 네트워크를 형성하고, 외부 데이터를 수신하여 네트워크에 속한 호스트로 데이터를 전송해주는 역할을 한다.
06. '잘 알려진 PORT(Well-known PORT')는 무엇이며, 그 값의 범위는 어떻게 되는가? 그리고 잘 알려진 PORT 중에서 대표적인 HTTP와 FTP의 PORT 번호가 어떻게 되는지 조사해보자.
답)
Well-known PORT는 예약된 PORT번호로 이 번호는 사용하게 되면 중복되므로 사용해서는 않되고, 범위는 0~1023번까지이다.
HTTP : 80, (HTTPS : 443)
FTP : 20, 21
07. 소켓에 주소를 할당하는 bind 함수의 프로토타입은 다음과 같다.
int bind(int sockfd, struct sockaddr* myaddr, socklen_t addrlen);그런데 호출은 다음의 형태로 이뤄진다.
bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr));여기서 serv_addr은 구조체 sockaddr_in의 변수이다. 그렇다면 bind 함수의 프로토타입과 달리 구조체 sockaddr_in의 변수를 사용하는 이유는 무엇인지 간단히 설명해보자.
답)
sockaddr와 sockaddr_in의 구조체 구조를 보면 쉽게 이해 할 수 있다.
struct sockaddr_in
{
sa_family_t sin_family; //주소체계(Address Family)
unit16_t sin_port; // 16비트 TCP/UDP PORT번호
struct in_addr sin_addr; // 32비트 IP주소
char sin_zero[8]; // 사용되지 않음
}
struct sockaddr
{
sa_familt_t sin_family; // 주소체계(Address Family)
char sa_data[14]; // 주소정보
}sockaddr의 sa_data에 IP Address와 PORT 번호가 정수값으로 변환되어 저장해야 한다. 변환하기 번거롭기 때문에 sa_data에 IP Address와 PORT번호를 채우는 것 보다는 sockaddr_in구조체의 sin_port와 sin_addr 변수에 채우는것이 훨씬 간편하다. 그래서 sockaddr_in 구조체 변수를 사용하며, bind() 함수 호출 시 'sockaddr_in' 을 'sockaddr* ' 형변환을 해주면 끝. (참고로 sin_zero는 sockaddr의 구조체 크기와 일치시키기 위해 추가한 변수일 뿐 아무 의미없는 변수이다.)
08. 빅 엔디안과 리틀 엔디안에 대해서 설명하고, 네트워크 바이트 순서가 무엇인지, 그리고 이것이 필요한 이유는 또 무엇인지 설명해보자.
답)
메모리에 데이터를 저장하는 방식이다. 빅 엔디안은 데이터를 최상위 비트부터 채우는 것을 의미하며, 리틀 엔디안은 데이터를 최하위 비트부터 채우는 것을 의미한다. 예를 들어 0x1234라는 데이터를 빅 엔디안, 리틀 엔디안 방식으로 메모리에 저장하면, 0x1234, 0x3412이다.
각 두 엔디안이 나온 이유 그리고 장점은 각각 이러하다. 빅 엔디안은 디버그를 편하게 해준다. 사람이 숫자를 읽고 쓰는 방식과 동일하게 데이터를 저장하므로 별도의 계산이 필요 없다. 리틀 엔디안은 메모리에 저장된 값의 하위 바이트들만 사용할 떄 별도의 계산을 하지 않아도 된다.
(참고로 인텔 계열, ARM계열 CPU는 리틀 엔디안 방식으로 설계되며, 네트워크 통신 시에는 데이터 정렬을 빅 엔디안 방식으로 하기로 약속 되어있다.)
09. 빅 엔디안을 사용하는 컴퓨터에서 4바이트 정수 12를 리틀엔디안을 사용하는 컴퓨터에게 전송하려 한다. 이때 데이터의 전송과정에서 발생하는 엔디안의 변환과정을 설명해보자.
답)
네트워크 통신은 빅 엔디안 방식으로 데이터를 전송하기로 약속되어 있기 때문에 12를 2진수로 변환하여 그대로 보내면 된다. 다만, 수신 시 리틀엔디안을 사용하는 컴퓨터이므로 수신된 데이터를 리틀 엔디안 방식으로 변환하여 저장해야 한다.
10. '루프백 주소(loopback address)'는 어떻게 표현되며, 의미하는 바는 무엇인가? 그리고 루프백 주소를 대상으로 데이터를 전송하면 어떠한 일이 벌어지는가?
답)
127.0.0.1로 표현되며, 로컬 컴퓨터의 IP Address를 의미한다. 루프백 주소를 대상으로 데이터를 전송하면 전송과 수신 대상이 모두 같은 로컬 컴퓨터에서 이루어 진다.
'네트워크 > 열혈 TCP_IP 소켓프로그래밍' 카테고리의 다른 글
| #6. UDP 기반 서버/클라이언트 (0) | 2022.08.02 |
|---|---|
| #5. TCP 기반 서버/클라이언트 2 (0) | 2022.07.30 |
| #4. TCP기반 서버/클라이언트 1 (0) | 2022.07.24 |
| #2. 소켓의 타입과 프로토콜의 설정 (0) | 2022.07.13 |
| #1. 네트워크 프로그래밍과 소켓의 이해 (0) | 2022.07.11 |



